
¿Cómo interconectamos los agentes?
En este momento se están planteando diferentes retos que hace tan sólo cinco años eran sólo teoría en la Inteligencia Artificial. Y lo más sorprendente es que ocurra a partir del desarrollo de modelos de lenguaje dado que en principio fueron diseñados para diferentes finalidades como conseguir una buena traducción de idiomas o la generación de texto coherente, pero se han demostrado capaces de desarrollar cierta capacidad de razonamiento, quizá por el propio tratamiento de ingentes cantidades de textos.
Con modelos más recientes como los modelos o3 y o1 de OpenAI o el competidor chino Deepseek, se ha alcanzado una capacidad de análisis y razonamiento que plantea un escenario diferente al que inicialmente estaba previsto: se pueden construir agentes inteligentes con cierta capacidad autónoma y cuyo funcionamiento sea óptimo. Esto es, podemos plantear que la construcción de agentes es mucho más asequible, menos costoso y sobre todo accesible a cualquier equipo técnico con capacidad para definirlos.
Incluso sin utilizar los modelos más complejos y costosos, sino aquellos que ya han sido entrenados en los últimos dos años con la capacidad de utilizar herramientas o llamadas a funciones (tools / function calling), podemos construir agentes que requieren una mínima capacidad de análisis y razonamiento para determinar con acierto aquellas herramientas que le permitan obtener un mejor resultado para responder a la «query» o solicitud que reciben.
Planteado el escenario en el que tenemos la posibilidad de desarrollar agentes inteligentes que realizan tareas específicas, podríamos pensar en el siguiente escenario: que tengamos decenas o centenares de agentes inteligentes y necesitamos que conecten entre ellos de forma que puedan interactuar para obtener el mejor resultado posible. Y aquí surge el principal inconveniente: no hemos determinado aún cuál es la estructura más adecuada para hacerlo. Por tanto, voy a bosquejar por aquí algunas de las ideas que se han planteado en diferentes estudios científicos al respecto para que podáis realizar vuestro propio análisis y planificar una solución en caso de que ya os encontréis en la tesitura de interconectar “inteligentemente” una gran cantidad de agentes.

¿Y por qué no usamos MCP?
El Model Context Protocol (MCP) es un protocolo abierto fundamental para que los agentes basados en Large Language Models (LLM) interactúen con herramientas, datos y servicios externos. Su principal utilidad es estandarizar y simplificar esta conexión entre un agente y los recursos que necesita utilizar, mejorando la interoperabilidad, escalabilidad y seguridad al desacoplar la invocación de herramientas directamente del LLM. Permite a los agentes descubrir y usar recursos de forma eficiente.
A pesar de ser muy eficaz para conectar a un agente con el «mundo exterior» a través de herramientas, el MCP se centra en la interacción de un agente individual que actúa como cliente llamando a servidores de herramientas. Este modelo es centralizado y no está diseñado inherentemente para la comunicación directa ni la colaboración compleja que requieren los sistemas con múltiples agentes autónomos que deben interactuar y coordinarse entre sí para lograr objetivos compartidos.
Por lo tanto, para facilitar la verdadera colaboración entre agentes, el intercambio de información, la negociación o la coordinación de tareas, se requieren otros protocolos interagentes específicos, esenciales para permitir que los sistemas multi-agente aborden tareas complejas y distribuidas y conseguir una “inteligencia colectiva”, un rol que difiere del enfoque de MCP en la interacción agente-a-recurso.

¿Y entonces qué protocolos tenemos disponibles para interconectar agentes?
Ya se han definido en la comunidad científica diversos protocolos y sistemas para facilitar la interconexión y colaboración entre agentes de IA. A continuación veremos algunos de ellos, diseñados para la comunicación directa y colaboración entre múltiples agentes autónomos que son esenciales para sistemas multi-agente y tareas complejas que requieren coordinación.
A2A (Agent-to-Agent Protocol): Desarrollado por Google, enfocado en la comunicación y colaboración fluida entre agentes independientemente de su tecnología o proveedor. Utiliza APIs basadas en HTTP y formato JSON. Soporta descubrimiento de agentes a través de «Agent Cards» y define flujos para la gestión de tareas. Está diseñado para la colaboración compleja, a menudo dentro de entornos empresariales.
ANP (Agent Network Protocol): Impulsado por la comunidad, busca la interoperabilidad cross-domain entre agentes. Su visión es crear un «Internet de Agentes» abierto y colaborativo. Emplea JSON-LD y DID (Identificadores Descentralizados) para la identidad y la interoperabilidad. Contempla una arquitectura por capas que puede incluir una capa de meta-protocolo.
Agora: Propuesto como un meta-protocolo que permite a los agentes negociar y adoptar dinámicamente diferentes protocolos de comunicación utilizando las capacidades de los LLM. Permite la adaptación a diversas necesidades de interacción.
AITP (Agent Interaction & Transaction Protocol): Desarrollado por NEAR Foundation, se centra en la comunicación segura y el intercambio de valor entre agentes a través de límites de confianza. Aborda la identidad, seguridad e integridad de datos utilizando Blockchain en entornos descentralizados.
AComP (Agent Communication Protocol): Protocolo en desarrollo por IBM para estandarizar la comunicación agente-a-agente y la colaboración. Busca simplificar la integración y eludir la dependencia de proveedores.
AConP (Agent Connect Protocol): De Cisco y Langchain, define una interfaz estándar (basada en OpenAPI y JSON) para invocar y configurar agentes. Si bien se centra en la interfaz de uso, puede emplearse para interconectar agentes.
LOKA Protocol: Un framework descentralizado que aborda identidad, rendición de cuentas y alineación ética en ecosistemas de agentes, particularmente en la interacción humano-agente, utilizando DIDs y VCs.
LMOS (Language Model Operating System): Un protocolo de interacción sistema-agente que proporciona una arquitectura para construir un «Internet de Agentes» (IoA) gestionado e interoperable, soportando descubrimiento, gestión y seguridad.
Agent Protocol (AI Engineer Foundation): Estándar para la interacción entre consolas de control y agentes, gestionando el ciclo de vida del agente a través de una interfaz unificada.
CrowdES y SPPs (Spatial Population Protocols): Protocolos orientados al dominio para la interacción robot-agente, centrados en la coordinación y el razonamiento espacial en entornos físicos.
Esta diversidad de protocolos refleja la variedad de escenarios (agente-a-recurso, agente-a-agente, dentro de una empresa, a través de dominios, interacciones específicas) y las diferentes necesidades (descubrimiento, colaboración, seguridad, estandarización, negociación, etc.) que surgen a medida que los sistemas multi-agente se vuelven más complejos y extendidos.
¿Y qué nos faltaría?
Por el momento no hay una definición clara de cuál será el protocolo que se convierta en estándar o el más usado para interconectar los agentes, pero aún faltaría un elemento fundamental: ¿cómo y dónde puede conectar un agente para saber qué funcionalidad o recursos permite cualquier otro agente de su “comunidad” o “espacio de trabajo”? Y para responder esto he de indicar que no hay demasiadas soluciones planteadas, aunque algunas de ellas son bastante intuitivas y sugerentes. Allá vamos:
He encontrado este protocolo, que en principio está diseñado para almacenar y responder a la selección de múltiples herramientas proporcionadas por servidores MCP, pero desde mi perspectiva se podría modificar para almacenar las descripciones de los agentes, ¿os parece? Allá va la descripción:
ScaleMCP: es un enfoque innovador para la selección e integración dinámica de herramientas en agentes basados en Large Language Models (LLM). Su propósito principal es permitir que los agentes descubran y utilicen herramientas externas, específicamente servidores que implementan el Model Context Protocol (MCP).

Una característica fundamental de ScaleMCP es su sistema de almacenamiento de herramientas auto-sincronizable. Este sistema considera a los servidores MCP como la única fuente de verdad para la información de las herramientas y utiliza operaciones CRUD (crear, leer, actualizar, eliminar) para mantener su propio índice de almacenamiento automáticamente actualizado. Esto resuelve los problemas de los repositorios de herramientas estáticos y las actualizaciones manuales.
Adopta un enfoque de Generación Aumentada con Recuperación (RAG) para agentes, equipando al agente LLM con una herramienta especializada de Recuperación de MCP. Esto otorga al agente la autonomía para buscar y seleccionar herramientas relevantes de forma dinámica, gestionar su «memoria» de herramientas durante interacciones de varios turnos y re-consultar si es necesario. Las herramientas recuperadas son cargadas en el contexto del LLM y utilizadas mediante function calling.
Además, ScaleMCP introduce TDWA (Tool Document Weighted Average), una nueva estrategia de embedding que permite ponderar la importancia de los diferentes componentes de la descripción de una herramienta (como el nombre, la descripción o preguntas sintéticas) al crear su representación vectorial. Este sistema mejora la interoperabilidad y escalabilidad al estandarizar cómo los agentes descubren y acceden a capacidades externas a través del protocolo MCP, permitiéndoles manejar y orquestar de forma autónoma y dinámica una gran cantidad de herramientas basadas en MCP.
Vamos ahora con otro enfoque:
AgentDNS es un sistema raíz de nombres de dominio y descubrimiento de servicios diseñado específicamente para agentes LLM. Su propósito fundamental es abordar la falta de protocolos y soluciones estandarizadas para el descubrimiento de servicios entre diferentes proveedores y herramientas en el ecosistema de agentes. Inspirado en los principios del sistema de nombres de dominio (DNS) tradicional de Internet, AgentDNS introduce un mecanismo estructurado para el registro, descubrimiento y resolución de servicios.
Este sistema establece un espacio de nombres unificado y semánticamente rico (por ejemplo, agentdns://org/category/name) para agentes y servicios, lo que permite desacoplar el nombre del identificador de servicio de sus direcciones físicas, como las URLs. Facilita el descubrimiento de servicios basado en lenguaje natural, permitiendo a los agentes consultar el servicio raíz de AgentDNS para encontrar agentes o servicios de terceros y obtener sus identificadores y metadatos asociados. Estos metadatos incluyen direcciones de red, capacidades detalladas y, de manera crucial, los protocolos de interoperabilidad o comunicación compatibles (como MCP, A2A, ANP). Esta característica, la interoperabilidad consciente del protocolo, permite a los agentes seleccionar de forma autónoma el protocolo adecuado para comunicarse, eliminando la necesidad de configuración manual.
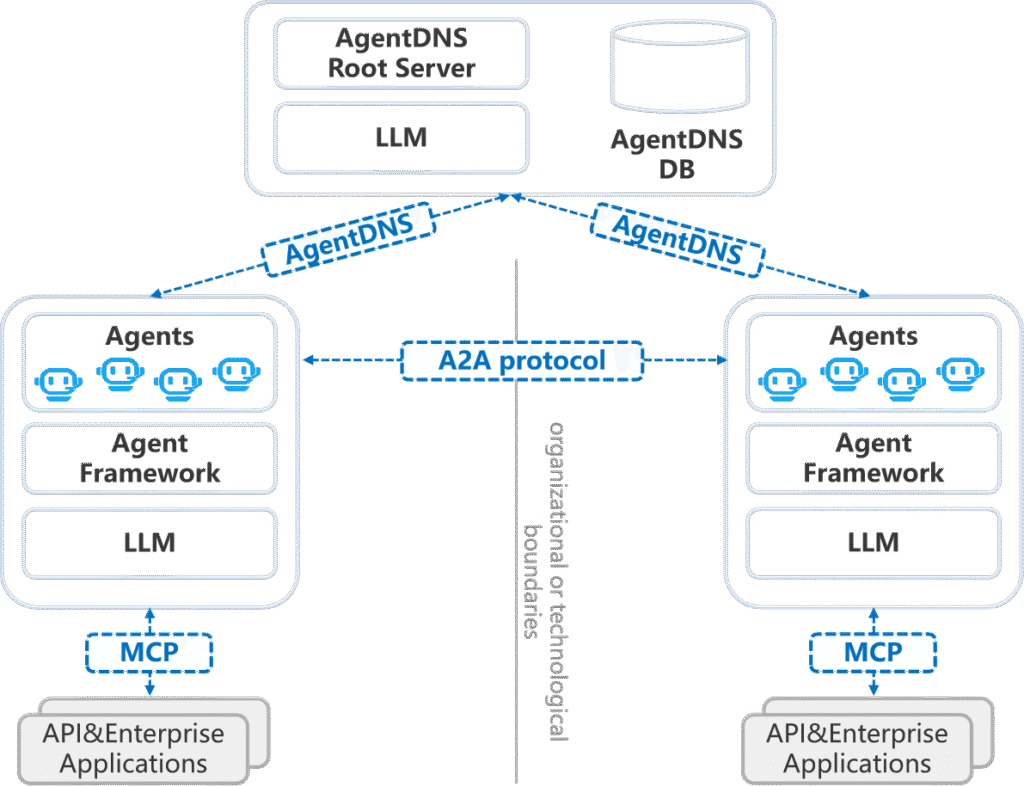
Además proporciona funcionalidad de resolución de servicios, permitiendo a los agentes que han almacenado en caché identificadores solicitar al servidor raíz la información más reciente de metadatos cuando sea necesario. Adicionalmente, introduce un mecanismo unificado de autenticación y facturación. Los agentes se autentican una vez con el servidor raíz de AgentDNS para obtener tokens de acceso que son válidos para todos los servicios registrados, reemplazando las claves API fragmentadas. AgentDNS centraliza el seguimiento de los costos de uso y maneja la liquidación con los proveedores individuales, simplificando el proceso de facturación para los usuarios. Funciona, por lo tanto, como un «libro de direcciones» dinámico que capacita a los agentes para descubrir, autenticarse e interoperar de manera segura y fluida a través de fronteras organizativas y tecnológicas. Su arquitectura incluye componentes clave para el registro, búsqueda, resolución, gestión, autenticación y facturación de servicios.
Pienso que AgentDNS es el planteamiento que más se puede acercar a lo que finalmente se adopte como estándar, así que habrá que estar atentos a la publicación del código en su repositorio de Github. Es un tema tan reciente y actual que sorprende la fecha de publicación del artículo: 28 de mayo de 2025.
Características principales del nuevo protocolo
Independientemente del protocolo que finalmente se erija en el más utilizado para la búsqueda y comunicación entre agentes, lo interesante es plantear los elementos principales que debería contener:
Directorio o índice de registro
Cada uno de los agentes participantes en la comunidad o espacio de trabajo definida, entendiendo que puede ser desde algo más doméstico y limitado como los agentes desplegados en un hogar para controlar la domótica, hasta algo más amplio como varios centenares de agentes de una gran empresa o administración pública. Tenemos diversas soluciones ya establecidas para el almacenamiento y búsqueda de recursos en forma de directorios eficientes tanto en el almacenamiento como en la búsqueda (por ejemplo LDAP). Por tanto necesitamos un espacio que contenga lo necesario de los agentes para poder gestionar la búsqueda.
Lo interesante de esta búsqueda es que se va a realizar en base a una descripción en lenguaje natural que construirán los propios agentes consultores del directorio. Algo así como “necesito un agente que realice la reserva de hotel….” o “necesito generar una imagen de una torre…”. De esta forma, el almacenamiento de las tarjetas o descripciones de los agentes debe ir acompañado de una base de datos vectorial o similar que gestione la similitud semántica con las consultas y sea capaz de devolver las credenciales de los agentes que más se ajustan a las “querys” recibidas.

Operaciones CRUD eficientes (semánticamente)
Dada la gran cantidad de agentes que puede llegar a tener nuestro ecosistema, resulta imprescindible que el directorio gestione los cambios (C:crear, R:read o leer, U:update o actualizar, D: delete o borrado) que se produzcan en los “contextos” de los agentes, es decir, modificación de la funcionalidad o los recursos que ofrecen. Algo que en los directorios conocidos hasta el momento ya es una trivialidad, en este caso supone un reto principalmente porque se está haciendo una gestión semántica del almacenamiento.
Con el planteamiento de ScaleMCP, podemos construir un embedding en base a las tarjetas de los agentes. Pero en el caso de que dicha tarjeta se actualice, tendrá que actualizarse también su vector-embedding en la base de datos semántica. Realizar esta operación se suma al requisito imprescindible de todo directorio que es la eficiencia en tiempo. Además se tendrán que definir procedimientos de evaluación y control del modelo de embedding y búsqueda semántica, siendo necesario definir tanto los parámetros que queremos controlar (exactitud, precisión, etc.) así como los umbrales de los valores de cada uno de ellos.
Esto afectaría sobre todo a la gestión de consultas, es decir, la operación de lectura (Read) del directorio. Será la más importante, la que habrá que cuidar con más atención tanto en eficiencia temporal (latencia mínima) como en la precisión de las respuestas. No servirá demasiado si, una vez planteada una búsqueda en base a una descripción, se devuelven credenciales de agentes que realmente no resuelven la tarea requerida.
Algunas cuestiones Pendientes
Pero aún quedarían varias cuestiones por resolver, como puede ser: ¿qué ocurre si para resolver una tarea no hay un agente concreto para resolverla sino que serán una secuencia de tareas/agentes las que conduzcan al objetivo? Es decir, tendrá que existir un razonamiento y división en tareas del problema inicial, además de la planificación de las mismas. Para ello, la interacción del “agente consultor” con el directorio puede ser diferente, o incluso se podría plantear que el directorio contenga un módulo “analizador/planificador” que en base a la consulta devuelva la secuencia de agentes y tareas que se deben ejecutar. Continuaremos investigando sobre este tema.


